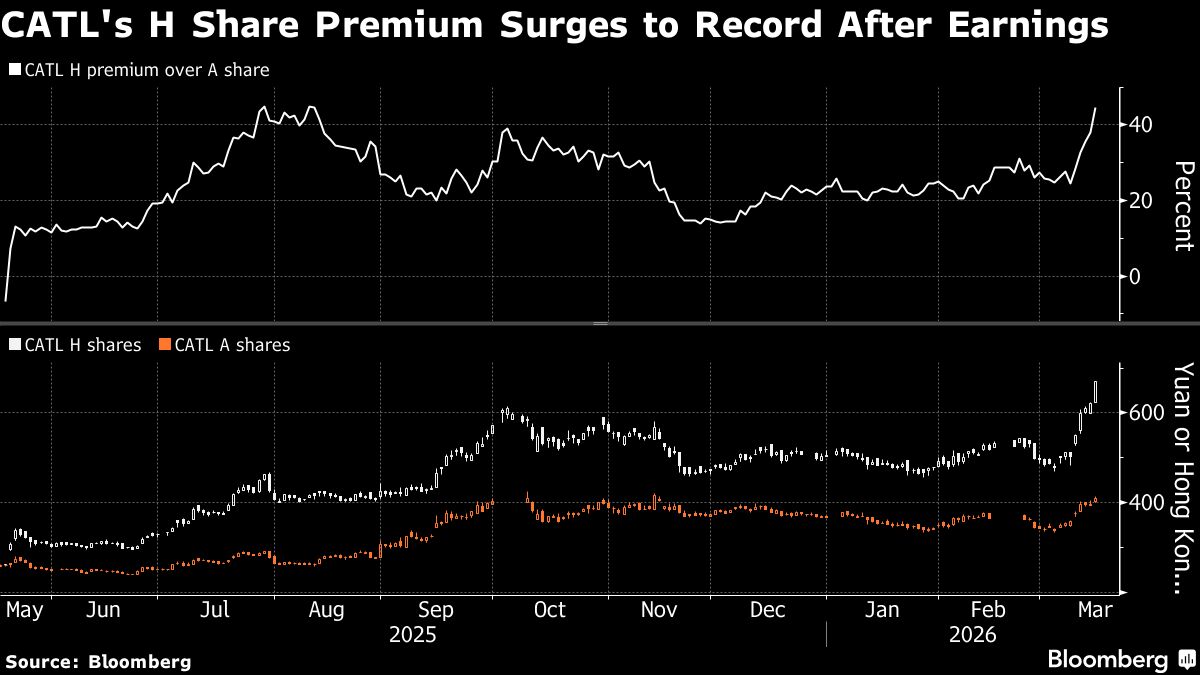
Introduction
In the realm of Artificial Intelligence (AI) and Natural Language Processing (NLP), one of the most pressing challenges is how to represent data, especially textual data, in a form that machines can understand. Traditional methods of representing words, like one-hot encoding, can be inefficient and fail to capture the semantic relationships between words. This is where embeddings come into play.
Embeddings are dense vector representations of words, phrases, or even entire sentences that capture the contextual meaning of the data. They allow models to learn relationships and similarities among different linguistic elements, leading to better performance in tasks such as sentiment analysis, machine translation, and information retrieval. In this article, we will explore the concept of embeddings, discuss various methods to create them, and provide practical implementations, comparisons, and case studies.
What Are Embeddings?
Definition and Importance
Embeddings are numerical representations of categorical data where similar items have similar representations. In the context of language, embeddings convert words or phrases into vectors in a continuous vector space. This allows models to learn from the relationships between words based on their contexts.
Importance of Embeddings:
- Dimensionality Reduction: Embeddings reduce the dimensionality of data while preserving relationships.
- Semantic Relationships: Words with similar meanings are represented by similar vectors.
- Improved Performance: Models utilizing embeddings often perform better in NLP tasks.
Step-by-Step Technical Explanation
Basic Concepts
-
Vector Space Model:
- Each word is represented as a point in a high-dimensional space.
- The distance between points indicates the semantic similarity.
-
Contextual Representation:
- Instead of treating words as isolated entities, embeddings capture their meanings based on context.
Popular Methods of Creating Embeddings
1. Word2Vec
Developed by Google, Word2Vec is one of the most popular methods for generating word embeddings. It uses either the Skip-Gram or Continuous Bag of Words (CBOW) model.
- Skip-Gram: Predicts surrounding words given a target word.
- CBOW: Predicts the target word from surrounding words.
Code Example using Gensim:
python
from gensim.models import Word2Vec
sentences = [[“the”, “dog”, “barked”], [“the”, “cat”, “meowed”], [“the”, “bird”, “sang”]]
model = Word2Vec(sentences, vector_size=10, window=2, min_count=1, sg=1)
dog_vector = model.wv[‘dog’]
print(dog_vector)
2. GloVe (Global Vectors for Word Representation)
GloVe is an unsupervised learning algorithm for obtaining vector representations for words. It leverages global word-word co-occurrence statistics from a corpus.
Code Example using GloVe:
To use GloVe, you typically need pre-trained vectors. Here’s how you might load them:
python
import numpy as np
glove_file = ‘glove.6B.50d.txt’
glove_vectors = {}
with open(glove_file, ‘r’, encoding=’utf-8′) as f:
for line in f:
values = line.split()
word = values[0]
vector = np.array(values[1:], dtype=’float32′)
glove_vectors[word] = vector
vector_dog = glove_vectors[‘dog’]
print(vector_dog)
3. FastText
FastText, developed by Facebook, improves upon Word2Vec by representing words as bags of character n-grams, allowing it to generate embeddings for out-of-vocabulary words.
Code Example using FastText:
python
from gensim.models import FastText
sentences = [[“the”, “dog”, “barked”], [“the”, “cat”, “meowed”], [“the”, “bird”, “sang”]]
model = FastText(sentences, vector_size=10, window=2, min_count=1)
dog_vector_fasttext = model.wv[‘dog’]
print(dog_vector_fasttext)
Advanced Concepts
1. Sentence and Document Embeddings
While word embeddings are useful, sometimes we need to represent entire sentences or documents. Techniques such as Universal Sentence Encoder and BERT (Bidirectional Encoder Representations from Transformers) can be used.
- Universal Sentence Encoder (USE): Provides embeddings for sentences by averaging word embeddings or using a transformer model.
Code Example using TensorFlow’s USE:
python
import tensorflow_hub as hub
embed = hub.load(“https://tfhub.dev/google/universal-sentence-encoder/4“)
sentences = [“The dog barked.”, “The cat meowed.”]
sentence_embeddings = embed(sentences)
print(sentence_embeddings)
2. Contextualized Embeddings
Recent advancements in AI have led to models that generate embeddings that change based on the context, such as BERT and ELMo.
- BERT: Uses attention mechanisms to provide contextual embeddings.
Code Example using Hugging Face Transformers:
python
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased’)
model = BertModel.from_pretrained(‘bert-base-uncased’)
text = “The dog barked.”
inputs = tokenizer(text, return_tensors=’pt’)
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
print(embeddings)
Comparison of Different Embedding Approaches
| Approach | Type | Contextual | Pre-trained Available | Suitable for OOV Words |
|---|---|---|---|---|
| Word2Vec | Word | No | Yes | No |
| GloVe | Word | No | Yes | No |
| FastText | Word | No | Yes | Yes |
| Universal Sentence Encoder | Sentence | No | Yes | N/A |
| BERT | Contextual | Yes | Yes | Yes |
Visualization of Embedding Spaces
Using a simple scatter plot, we can visualize how different words might cluster together in a 2D space based on their embeddings.
mermaid
graph TD;
A[Dog] –> B[Cat]
A –> C[Animal]
D[Car] –> E[Vehicle]
D –> F[Transportation]
A –> G[Pet]
B –> G
Case Studies
Case Study 1: Sentiment Analysis
A company wants to analyze customer reviews to understand sentiment. By using FastText, they can create embeddings for words in reviews and then train a classifier to predict sentiment.
- Data Collection: Gather customer reviews.
- Preprocessing: Clean and tokenize the text.
- Embedding Creation: Use FastText to create word embeddings.
- Model Training: Train a classifier (e.g., Logistic Regression).
- Evaluation: Assess model performance using accuracy and F1 score.
Case Study 2: Chatbot Development
A startup is developing a customer service chatbot. By utilizing BERT for generating contextual embeddings, the chatbot can better understand user queries.
- User Queries: Collect common user questions.
- Embedding Generation: Use BERT to generate embeddings for these queries.
- Intent Recognition: Train a model to classify intents based on embeddings.
- Response Generation: Use embeddings to fetch or generate appropriate responses.
Conclusion
Embeddings are a powerful tool in the AI toolkit, enabling models to understand and process language more effectively. By representing words and sentences in a continuous vector space, embeddings help capture semantic relationships and improve model performance across various tasks.
Key Takeaways
- Understanding Context: Contextual embeddings are crucial for capturing the nuances of language.
- Model Selection: Choose the appropriate embedding technique based on your specific task and data availability.
- Pre-trained Models: Utilizing pre-trained embeddings can save time and improve performance, especially in NLP tasks.
Best Practices
- Experiment with different embedding approaches to find the one that works best for your application.
- Use embeddings in conjunction with other techniques, such as fine-tuning models on your specific datasets.
- Keep abreast of the latest advancements in embedding techniques, as this field is rapidly evolving.
Useful Resources
-
Libraries:
-
Frameworks:
-
Research Papers:
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. NeurIPS 2013.
- Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global Vectors for Word Representation. EMNLP 2014.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
By utilizing embeddings effectively, you can significantly enhance your models’ capabilities in understanding and processing language, paving the way for more intelligent AI applications.